Lecture 4: Model Improvements and Pipelines
Contents
Lecture 4: Model Improvements and Pipelines#
In this lecture we are going to build upon the knowledge of last week(s). We will combine data preprocessing steps with ML models and crete data pipelines. In addition, a few tips of model improvements (class imbalance) will be discussed.
This week you will learn:
Something about Random-forest and deep learning.
How to combine data-preprocessing and modelling in a data pipeline.
How to use different models on a given, practical problem.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import OneHotEncoder, StandardScaler, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from generate_dataset import generate_dataset
To illustrate where we currrently are I am reposing the schema below from last week. Un this class we will zoom in further on classification.
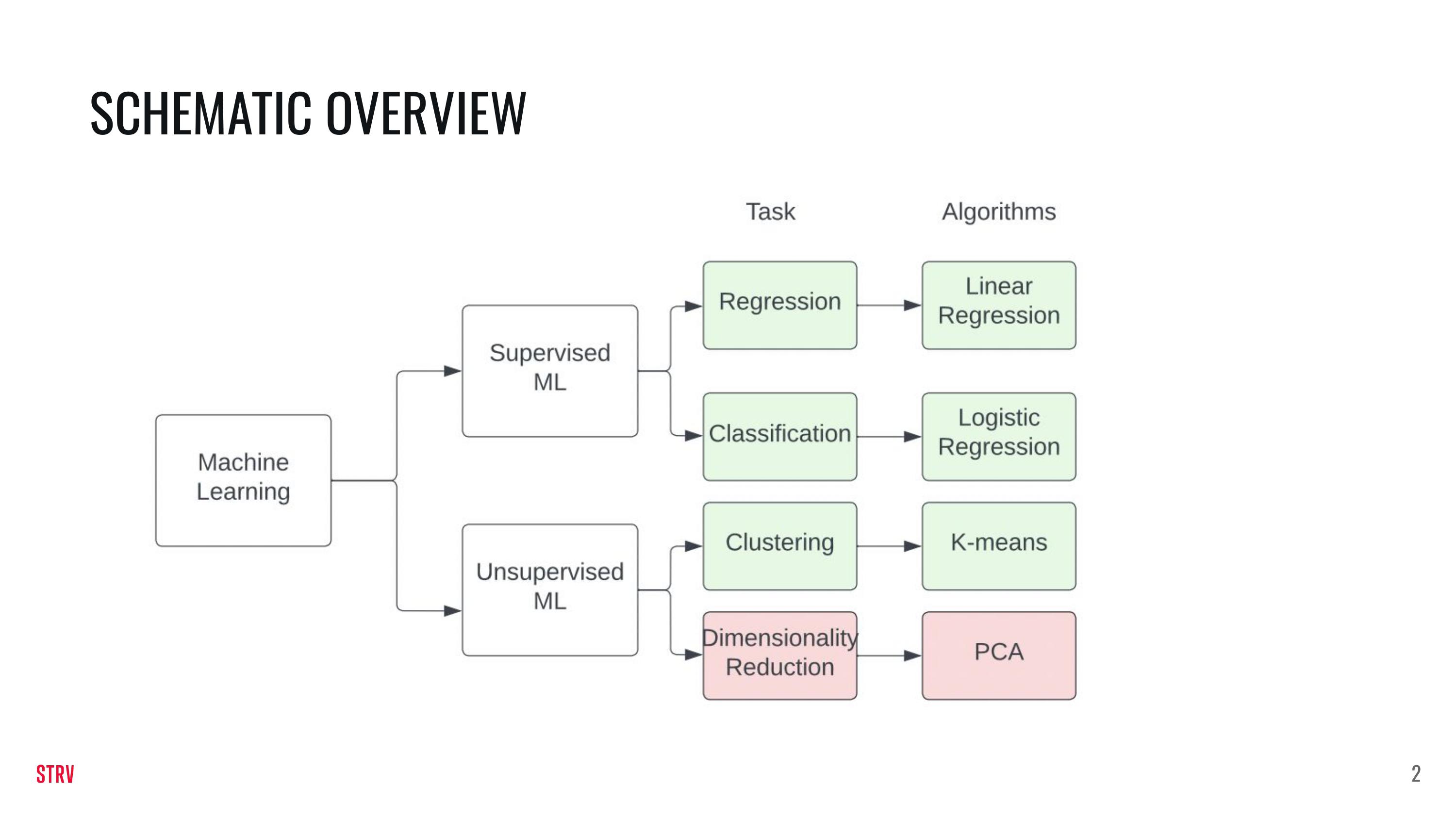
In this lecture we will discuss and apply several ML-algorithms.
The main models of this lecture are:
Logistic Regression (see previous lecture)
Random Forest (a decision tree)
Neural Network
I will briefly discuss them.
The slide below was shown in last week’s presentation. A reminder that logistic regression is a linear classifier.

The second model is the Random Forest, which is basically a collection of decision trees. A classical decision tree is shown below. The question is “should I play badminton?”

A single decision tree is unstable. For this reason we generate many of them and then average the predictions. A Random Forest is not a linear classifier and can thus be vary useful.

And finally we will use Neural Networks. The image below shows a single hidden layer, but the number of hidden layers can ofcource vary (deep learning). The mathematical idea is that we can fit almost every function by just adding hidden layers. The more layers we add, the more complex our functions can become. This allowed for lost of breakthroughs in many fields (e.g. computer vision and NLP) in the last ten years.

Data Pipeline#
To illustrate the use of data pipelines, we are going to generate data using a function that I created (see generate_dataset.py). The task will be a classification task and will contain both numerical and categorical features. Unlike last we week, we will use the sklearn function make_classification to generate our data.
from secrets import choice
X_train, X_test, y_train, y_test = generate_dataset()
For our data pipeline, we need to know which features are categorical or numerical. Both types of variables require different steps in the preprocessing pipeline. Categorical features need to be numerically encoded (e.g: 1h-encoding). Numerical features need (in many cases) to be standardized (see lecture 2).
categorical_cols = [column for column in X_train.columns if 'categorical' in column]
numerical_cols = [column for column in X_train.columns if 'numerical' in column]
We will now create a pipeline using ColumnTransformer and Pipeline from sklearn.
# create ColumnTransformer, and pass the column names to transform in each step
def make_pipeline(categorical_cols=[], numerical_cols=[], classifier=LogisticRegression()):
preprocessor = ColumnTransformer(
[
('ohe', OneHotEncoder(drop='first', handle_unknown='ignore'), categorical_cols),
('scale', StandardScaler(), numerical_cols)
]
)
clf = Pipeline(
steps=[
('preprocessor', preprocessor),
('classifier', classifier)
]
)
return clf
Now that we have defined our pipeline, let’s see how different models will perform on our generated data. We define the models that we want to test in the list below.
models_to_run = [
LogisticRegression(multi_class='multinomial'),
RandomForestClassifier(max_depth=2),
RandomForestClassifier(max_depth=5),
RandomForestClassifier(max_depth=10),
RandomForestClassifier(max_depth=20),
RandomForestClassifier(max_depth=80),
MLPClassifier(hidden_layer_sizes=2),
MLPClassifier(hidden_layer_sizes=6),
MLPClassifier(hidden_layer_sizes=10),
MLPClassifier(hidden_layer_sizes=20),
MLPClassifier(hidden_layer_sizes=40)
]
The standard classification metric to evaluate models in sklearn pipelines is the Accuracy. The Accuracy is the number of correct predictions out of all the datapoints. This metric works ok in generic situations, but might not be the best in cases where the distribution of the target, y, is not even. This situation is normally referred to as unbalanced.
We will quickly assess our target distribution to see if it is balancef or unbalanced before we continue.
plt.pie(np.bincount(y_train) / len(y_train), labels=np.unique(y_train))
([<matplotlib.patches.Wedge at 0x7f0f8a5742e0>,
<matplotlib.patches.Wedge at 0x7f0f8a574760>,
<matplotlib.patches.Wedge at 0x7f0f8a574be0>],
[Text(0.5258866840431149, 0.9661486405031771, '0'),
Text(-1.0986106518112515, -0.055268759049369474, '1'),
Text(0.5737659537757365, -0.9385055302382718, '2')])
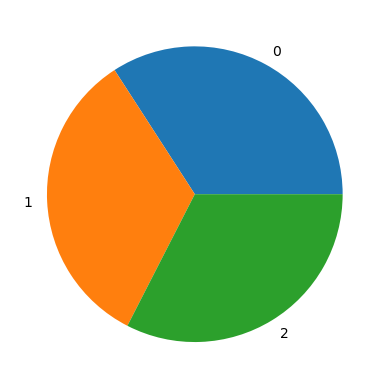
The distribution is approximately even, so the Accuracy will suffice. We will now run the models on our data, store the clasification results (the Accuracy!) and show them using a pandas dataframe.
results = {}
for model in models_to_run:
# create instance of the class, feed the model to be tested
clf = make_pipeline(categorical_cols, numerical_cols, model)
clf.fit(X_train, y_train)
# store results in a dictionary
results[str(model)] = clf.score(X_test, y_test)
pd.DataFrame.from_dict(results, orient='index', columns=['score'])
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
| score | |
|---|---|
| LogisticRegression(multi_class='multinomial') | 0.488 |
| RandomForestClassifier(max_depth=2) | 0.588 |
| RandomForestClassifier(max_depth=5) | 0.776 |
| RandomForestClassifier(max_depth=10) | 0.780 |
| RandomForestClassifier(max_depth=20) | 0.768 |
| RandomForestClassifier(max_depth=80) | 0.768 |
| MLPClassifier(hidden_layer_sizes=2) | 0.468 |
| MLPClassifier(hidden_layer_sizes=6) | 0.624 |
| MLPClassifier(hidden_layer_sizes=10) | 0.668 |
| MLPClassifier(hidden_layer_sizes=20) | 0.712 |
| MLPClassifier(hidden_layer_sizes=40) | 0.728 |
There are big differences between the performances, but the random forest and the neural network seem to be the big winners. Clearly, there is something to gain from upgrading from the simple logstic regression to RF or NN. So what exactly are the the weak/strong points of these algorithm and how do we know when to use which one?
LOGISTIC REGRESSION#
Advantages: interpretable results and should be used in cases where you want to understand relationships.
Disadvantages: often not able to capture complex/relationships and doesn’t work well out of the box if non-linearities are present.
RANDOM FOREST#
Advantages: works very well out of the box. Is resilient against overfitting and is able to capture complex (non-linear) relationships. Almost no data-preprocessing is needed!
Disadvantages: there are many hyperparamers to tune, not as interpretable as logistic regression.
Neural Network#
Advantages: can theoretically model any relation. Can lead to very high results, IF tuned properly.
Disadvantages: very easy to overfit, designing a model can take a long time, almost no interpretability.
WINE DATASET#
So, let’s see how well our pipeline will perform on some real-world examples. Our first stop is the famous ‘wine’ dataset, where we ought to predict the quality of wines given several features.
wine = pd.read_csv('../../static/data/winequality-red.csv')
y_wine = wine['quality']
X_wine = wine.drop(['quality'], axis=1)
This dataset is actually a regression problem, but we will change it into a classification problem by grouping the target. We will create two groups: ‘medium’ with all rating up to and including 6, and ‘excellent’ containg all ratings from 7.
# Create Classification version of target variable
y_wine = pd.Series([1 if x >= 7 else 0 for x in y_wine])
y_wine = y_wine.replace({0: 'medium', 1: 'excellent'})
So what do our features look like?
X_wine.head()
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 |
| 1 | 7.8 | 0.88 | 0.00 | 2.6 | 0.098 | 25.0 | 67.0 | 0.9968 | 3.20 | 0.68 | 9.8 |
| 2 | 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15.0 | 54.0 | 0.9970 | 3.26 | 0.65 | 9.8 |
| 3 | 11.2 | 0.28 | 0.56 | 1.9 | 0.075 | 17.0 | 60.0 | 0.9980 | 3.16 | 0.58 | 9.8 |
| 4 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 |
Do we have any categorical feature hiding in our dataset that we would want to one-hot-encode with our pipeline?
Remember that a categorical feature often has a low number of unique values.
X_wine.nunique()
fixed acidity 96
volatile acidity 143
citric acid 80
residual sugar 91
chlorides 153
free sulfur dioxide 60
total sulfur dioxide 144
density 436
pH 89
sulphates 96
alcohol 65
dtype: int64
Thw output above shows the number of unique values per feature. If the number of unique values is low, it could be an indication that it is better to treat the variable as categorical (make them a string).
The dataset has a total of 1600 rows (or observations), so in this case I would say that it is ok to treat all the variables as numerical.
For class balance we have to plot the distribution of the target again.
labels_wine, counts_wine = np.unique(y_wine, return_counts=True)
plt.pie(counts_wine / len(y_wine), labels=labels_wine, autopct='%1.1f%%')
plt.title('Distribution of wine labels')
plt.axis('equal')
plt.show()
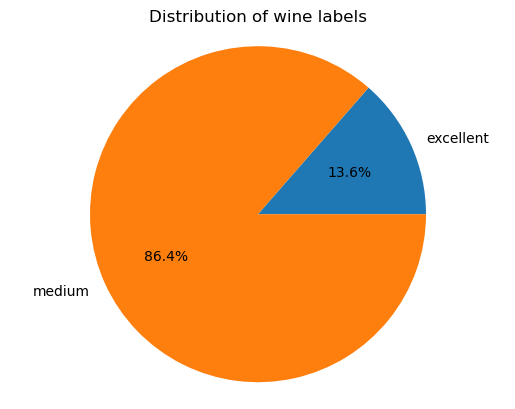
The distribution of the labels is a off. It means that we can get 86% accuracy by always predicting ‘medium’. Therefor we need a metric that somehow corrects for this. We find our corrected metric in someone called the ‘F1 score’. We will also try to ‘fix’ the class imbalance by adding a parameter to our pipeline.
X_train_wine, X_test_wine, y_train_wine, y_test_wine = train_test_split(X_wine, y_wine, test_size=.50, random_state=15)
We dont have categorical features in our dataset, so we dont need to process them. We standardize all of our features!
categorical_cols = []
numerical_cols = X_train_wine.columns
from sklearn.metrics import f1_score
results = {}
for model in models_to_run:
# create instance of the class, feed the model to be tested
clf = make_pipeline(categorical_cols, numerical_cols, model)
clf.fit(X_train_wine, y_train_wine)
# store results in a dictionary
results[str(model)] = f1_score(y_test_wine, clf.predict(X_test_wine), average='weighted')
pd.DataFrame.from_dict(results, orient='index', columns=['score'])
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
| score | |
|---|---|
| LogisticRegression(multi_class='multinomial') | 0.868228 |
| RandomForestClassifier(max_depth=2) | 0.822008 |
| RandomForestClassifier(max_depth=5) | 0.875235 |
| RandomForestClassifier(max_depth=10) | 0.897810 |
| RandomForestClassifier(max_depth=20) | 0.906959 |
| RandomForestClassifier(max_depth=80) | 0.905877 |
| MLPClassifier(hidden_layer_sizes=2) | 0.826647 |
| MLPClassifier(hidden_layer_sizes=6) | 0.866706 |
| MLPClassifier(hidden_layer_sizes=10) | 0.874667 |
| MLPClassifier(hidden_layer_sizes=20) | 0.869089 |
| MLPClassifier(hidden_layer_sizes=40) | 0.874326 |
An interesting observation is that the Neural Network does not seem to do much better than the Random Forest. Ofcourse, this might be different with proper hyperparameter tuning (see next week!), but something else must be mentioned. On tabular data (data that fit into an excel spreadsheet), Neural Networks might not be the best choice. A Random Forest, on the other hand, tends to have a good performance on tabular data.
Our minority class (excellent wines!) only has an occurence of 13%. Luckily there is a trick in sklearn’s random forest algorithm, a single parameter that we can use in order to correct for this. This parameter is called class_weight and we want to set it to balanced in order to tackle class imbalance.
It to our pipeline we do this as follows:
# create ColumnTransformer, and pass the column names to transform in each step
def make_pipeline(categorical_cols=[], numerical_cols=[], classifier=LogisticRegression()):
if isinstance(classifier, RandomForestClassifier):
setattr(classifier, 'class_weight', 'balanced')
preprocessor = ColumnTransformer(
[
('ohe', OneHotEncoder(drop='first', handle_unknown='ignore'), categorical_cols),
('scale', StandardScaler(), numerical_cols)
]
)
clf = Pipeline(
steps=[
('preprocessor', preprocessor),
('classifier', classifier)
]
)
return clf
from sklearn.metrics import f1_score
results = {}
for model in models_to_run:
# create instance of the class, feed the model to be tested
clf = make_pipeline(categorical_cols, numerical_cols, model)
clf.fit(X_train_wine, y_train_wine)
# store results in a dictionary
results[str(model)] = f1_score(y_test_wine, clf.predict(X_test_wine), average='weighted')
pd.DataFrame.from_dict(results, orient='index', columns=['score'])
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/neural_network/_multilayer_perceptron.py:702: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
warnings.warn(
| score | |
|---|---|
| LogisticRegression(multi_class='multinomial') | 0.868228 |
| RandomForestClassifier(class_weight='balanced', max_depth=2) | 0.825516 |
| RandomForestClassifier(class_weight='balanced', max_depth=5) | 0.862949 |
| RandomForestClassifier(class_weight='balanced', max_depth=10) | 0.896311 |
| RandomForestClassifier(class_weight='balanced', max_depth=20) | 0.895385 |
| RandomForestClassifier(class_weight='balanced', max_depth=80) | 0.900999 |
| MLPClassifier(hidden_layer_sizes=2) | 0.850417 |
| MLPClassifier(hidden_layer_sizes=6) | 0.863810 |
| MLPClassifier(hidden_layer_sizes=10) | 0.855434 |
| MLPClassifier(hidden_layer_sizes=20) | 0.861475 |
| MLPClassifier(hidden_layer_sizes=40) | 0.875574 |
Unfortunately the parameter did not change our model for the better. This can ofcourse always happen in Machine Learning, which is sometimes more of an art than a science. Several other methods to combat class imbalance could be checked for (oversampling, smote…), but an increase in performance is never guaruanteed.
IN PRACTICE: MNIST DATASET#
We will turn to a second problem: the classification of handwritten digits. This is a computer vision task, and we know that Logistic Regression and Random Forest are ill-equipped for this task. Instead, we will add a convolutional neural network to our pipeline.
from tensorflow.keras.datasets.mnist import load_data
from tensorflow.keras import Sequential
from tensorflow.keras.utils import plot_model
from tensorflow.keras.datasets.mnist import load_data
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
from tensorflow.keras.layers import (
Conv2D,
Dense,
Dropout,
Flatten,
MaxPool2D
)
from sklearn.datasets import load_digits
(X_digits_train, y_digits_train), (X_digits_test, y_digits_test) = load_data()
So what does our data look like?
X_digits_train[:, :, :]
array([[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
...,
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]], dtype=uint8)
X_digits_train.shape
(60000, 28, 28)
So it is important to understand that this dataset is fundamentally different than the datasets that we have seen so far. Before we were seeing N * P datasets, where N is the number of data points and P is the number of features. Our current dataset is N * H * W. N is still the number of data points, but H refers to the height of the image and W to its width. Every cell in this array has a number attached to it to determine its colour (0 = black).
Let’s see if we can plot some images.
plt.figure(figsize=(6,6)) # specifying the overall grid size
for i in range(4):
plt.subplot(2,2,i+1) # the number of images in the grid is 5*5 (25)
plt.imshow(X_digits_train[i])
plt.show()
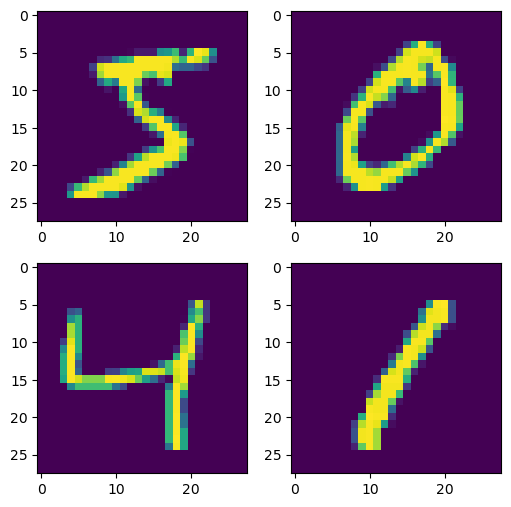
So the task is clear. We have these handwritten numbers and we will see if we can classify them correctly.
The models that we have seen so far, dont do good job on data like this. They do well on somewhat independent features, not on images with strong local correlations. We will, however, compare their (LR, RF..) performance to our new convolutional neural network.
To create our conv. neural network, we will turn to a library called tensorflow/Keras. For your understanding: Tensorflow is an ML/AI library that is optimized for mathematical operations. Keras is a library that runs on top of Tensorflow and does Deep Learning/Neural Networks. This library allows us to completely customize our neural network to our needs. A proper introduction to Tensorflow is outside the scope of this course, but in practice we stack layers after each other. The final layer returns 10 values, with a probability for each possible output (the number 0 up to 10).
# defining the model
inp_shape = X_digits_train.shape[1:]
def create_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=inp_shape + (1,)))
model.add(MaxPool2D((2, 2)))
model.add(Conv2D(48, (3, 3), activation='relu'))
model.add(MaxPool2D((2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
We wrap our model in KerasClassifier and then add it to our models_to_run.
nn_clasifier = KerasClassifier(build_fn=create_model, verbose=0)
models_to_run = [
LogisticRegression(multi_class='multinomial'),
RandomForestClassifier(max_depth=20),
MLPClassifier(hidden_layer_sizes=20),
nn_clasifier
]
Our convolutional network is able to handle images, but the other models cannot. These models expect a N * P input (two dimensions) and not a N * H * W input (three dimensions). For those models we will average over the third dimension to get to our N * P format. We will, ofcourse, lose information in the process.
# create ColumnTransformer, and pass the column names to transform in each step
from sklearn.preprocessing import FunctionTransformer
def mean_over_second_image_dimension(img):
return np.mean(img, axis=2)
transformer = FunctionTransformer(mean_over_second_image_dimension)
def make_pipeline_mnist(classifier=LogisticRegression()):
clf = Pipeline(
steps=[
('classifier', classifier)
]
)
# check if instance is KerasClassifier, if not, add first steo to reduce
# the dimensions
if not isinstance(classifier, KerasClassifier):
clf.steps.insert(0, ['estimator', transformer]) #insert as first step
return clf
Lets run the pipelines again and store our results
results = {}
for model in models_to_run:
# create instance of the class, feed the model to be tested
clf = make_pipeline_mnist(model)
clf.fit(X_digits_train, y_digits_train)
# store results in a dictionary
results[str(model)] = clf.score(X_digits_test, y_digits_test)
pd.DataFrame.from_dict(results, orient='index', columns=['score'])
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py:444: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
2022-10-25 17:29:35.653981: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE4.1 SSE4.2 AVX AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-10-25 17:29:35.725709: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
2022-10-25 17:29:35.742910: I tensorflow/core/platform/profile_utils/cpu_utils.cc:112] CPU Frequency: 3609600000 Hz
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In [31], line 5
2 for model in models_to_run:
3 # create instance of the class, feed the model to be tested
4 clf = make_pipeline_mnist(model)
----> 5 clf.fit(X_digits_train, y_digits_train)
7 # store results in a dictionary
8 results[str(model)] = clf.score(X_digits_test, y_digits_test)
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/sklearn/pipeline.py:382, in Pipeline.fit(self, X, y, **fit_params)
380 if self._final_estimator != "passthrough":
381 fit_params_last_step = fit_params_steps[self.steps[-1][0]]
--> 382 self._final_estimator.fit(Xt, y, **fit_params_last_step)
384 return self
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/keras/wrappers/scikit_learn.py:223, in KerasClassifier.fit(self, x, y, **kwargs)
221 raise ValueError('Invalid shape for y: ' + str(y.shape))
222 self.n_classes_ = len(self.classes_)
--> 223 return super(KerasClassifier, self).fit(x, y, **kwargs)
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/keras/wrappers/scikit_learn.py:166, in BaseWrapper.fit(self, x, y, **kwargs)
163 fit_args = copy.deepcopy(self.filter_sk_params(Sequential.fit))
164 fit_args.update(kwargs)
--> 166 history = self.model.fit(x, y, **fit_args)
168 return history
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/keras/engine/training.py:1095, in Model.fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, validation_batch_size, validation_freq, max_queue_size, workers, use_multiprocessing)
1088 with trace.Trace(
1089 'train',
1090 epoch_num=epoch,
1091 step_num=step,
1092 batch_size=batch_size,
1093 _r=1):
1094 callbacks.on_train_batch_begin(step)
-> 1095 tmp_logs = self.train_function(iterator)
1096 if data_handler.should_sync:
1097 context.async_wait()
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/eager/def_function.py:828, in Function.__call__(self, *args, **kwds)
826 tracing_count = self.experimental_get_tracing_count()
827 with trace.Trace(self._name) as tm:
--> 828 result = self._call(*args, **kwds)
829 compiler = "xla" if self._experimental_compile else "nonXla"
830 new_tracing_count = self.experimental_get_tracing_count()
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/eager/def_function.py:871, in Function._call(self, *args, **kwds)
868 try:
869 # This is the first call of __call__, so we have to initialize.
870 initializers = []
--> 871 self._initialize(args, kwds, add_initializers_to=initializers)
872 finally:
873 # At this point we know that the initialization is complete (or less
874 # interestingly an exception was raised) so we no longer need a lock.
875 self._lock.release()
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/eager/def_function.py:725, in Function._initialize(self, args, kwds, add_initializers_to)
722 self._lifted_initializer_graph = lifted_initializer_graph
723 self._graph_deleter = FunctionDeleter(self._lifted_initializer_graph)
724 self._concrete_stateful_fn = (
--> 725 self._stateful_fn._get_concrete_function_internal_garbage_collected( # pylint: disable=protected-access
726 *args, **kwds))
728 def invalid_creator_scope(*unused_args, **unused_kwds):
729 """Disables variable creation."""
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/eager/function.py:2969, in Function._get_concrete_function_internal_garbage_collected(self, *args, **kwargs)
2967 args, kwargs = None, None
2968 with self._lock:
-> 2969 graph_function, _ = self._maybe_define_function(args, kwargs)
2970 return graph_function
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/eager/function.py:3361, in Function._maybe_define_function(self, args, kwargs)
3357 return self._define_function_with_shape_relaxation(
3358 args, kwargs, flat_args, filtered_flat_args, cache_key_context)
3360 self._function_cache.missed.add(call_context_key)
-> 3361 graph_function = self._create_graph_function(args, kwargs)
3362 self._function_cache.primary[cache_key] = graph_function
3364 return graph_function, filtered_flat_args
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/eager/function.py:3196, in Function._create_graph_function(self, args, kwargs, override_flat_arg_shapes)
3191 missing_arg_names = [
3192 "%s_%d" % (arg, i) for i, arg in enumerate(missing_arg_names)
3193 ]
3194 arg_names = base_arg_names + missing_arg_names
3195 graph_function = ConcreteFunction(
-> 3196 func_graph_module.func_graph_from_py_func(
3197 self._name,
3198 self._python_function,
3199 args,
3200 kwargs,
3201 self.input_signature,
3202 autograph=self._autograph,
3203 autograph_options=self._autograph_options,
3204 arg_names=arg_names,
3205 override_flat_arg_shapes=override_flat_arg_shapes,
3206 capture_by_value=self._capture_by_value),
3207 self._function_attributes,
3208 function_spec=self.function_spec,
3209 # Tell the ConcreteFunction to clean up its graph once it goes out of
3210 # scope. This is not the default behavior since it gets used in some
3211 # places (like Keras) where the FuncGraph lives longer than the
3212 # ConcreteFunction.
3213 shared_func_graph=False)
3214 return graph_function
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/framework/func_graph.py:990, in func_graph_from_py_func(name, python_func, args, kwargs, signature, func_graph, autograph, autograph_options, add_control_dependencies, arg_names, op_return_value, collections, capture_by_value, override_flat_arg_shapes)
987 else:
988 _, original_func = tf_decorator.unwrap(python_func)
--> 990 func_outputs = python_func(*func_args, **func_kwargs)
992 # invariant: `func_outputs` contains only Tensors, CompositeTensors,
993 # TensorArrays and `None`s.
994 func_outputs = nest.map_structure(convert, func_outputs,
995 expand_composites=True)
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/eager/def_function.py:634, in Function._defun_with_scope.<locals>.wrapped_fn(*args, **kwds)
632 xla_context.Exit()
633 else:
--> 634 out = weak_wrapped_fn().__wrapped__(*args, **kwds)
635 return out
File ~/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/framework/func_graph.py:977, in func_graph_from_py_func.<locals>.wrapper(*args, **kwargs)
975 except Exception as e: # pylint:disable=broad-except
976 if hasattr(e, "ag_error_metadata"):
--> 977 raise e.ag_error_metadata.to_exception(e)
978 else:
979 raise
ValueError: in user code:
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/keras/engine/training.py:800 train_function *
return step_function(self, iterator)
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/keras/engine/training.py:790 step_function **
outputs = model.distribute_strategy.run(run_step, args=(data,))
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/distribute/distribute_lib.py:1259 run
return self._extended.call_for_each_replica(fn, args=args, kwargs=kwargs)
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/distribute/distribute_lib.py:2730 call_for_each_replica
return self._call_for_each_replica(fn, args, kwargs)
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/distribute/distribute_lib.py:3417 _call_for_each_replica
return fn(*args, **kwargs)
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/keras/engine/training.py:783 run_step **
outputs = model.train_step(data)
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/keras/engine/training.py:749 train_step
y_pred = self(x, training=True)
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/keras/engine/base_layer.py:998 __call__
input_spec.assert_input_compatibility(self.input_spec, inputs, self.name)
/home/jan/miniconda3/envs/ds-academy-development/lib/python3.9/site-packages/tensorflow/python/keras/engine/input_spec.py:234 assert_input_compatibility
raise ValueError('Input ' + str(input_index) + ' of layer ' +
ValueError: Input 0 of layer sequential is incompatible with the layer: : expected min_ndim=4, found ndim=3. Full shape received: (32, 28, 28)
As expected our convolutional network does a bitter job than the other algorithms! But, there are some tricks to upgrade their performances… see exercise!
Exercise / bonus tutorial#
Our previous method to reduce the dimensionality of the mnist inputs in order to prepare them for a Random Forest, is probably not the best. Instead of it, we will turn to a different approach.
In fact, we want to perform Dimensionality Reduction. This could also be achieved by the unsupervised ML-method of Principal Component Analysis (PCA). In this exercise, we will use this method to prepare our image data for a Random Forest.
load PCA from sklearn
from sklearn.decomposition import PCA
Replace the mean_over_second_image_dimension function by a reshape_image function. It should use np.reshape() and replace the 28 x 28 format by the 728 x 1 format.
# create ColumnTransformer, and pass the column names to transform in each step
from sklearn.preprocessing import FunctionTransformer
# def mean_over_second_image_dimension(img):
# return np.mean(img, axis=2)
def reshape_image(img):
# Your code here
Input In [33]
# Your code here
^
IndentationError: expected an indented block
Add both the transformation step from the previous cell, and PCA to the pipeline below. For PCA, use the parameter n_components=20.
def make_pipeline_mnist(classifier=LogisticRegression()):
clf = Pipeline(
steps=[
('classifier', classifier)
]
)
# check if instance is KerasClassifier, if not, add first steo to reduce
# the dimensions
if not isinstance(classifier, KerasClassifier):
# your code here
return clf
Run the new pipeline on all the previous models.
What is the upgrade in performance? ;-)